
在电影《黑客帝国》中,人类被想象为“生物电池”,机器从人类身体所产生的热量和电力中获取能量。这种设定虽然夸张,但引发了人们对于虚拟现实与现实世界之间的界限,以及自由意志等问题的思考。
电影中的“生物电池”概念也引出了一个有趣的现代对比:随着人工智能的发展,人们在某种程度上开始“为AI打工”。在大型文本生成项目中,如OpenAI的GPT系列,高性能的AI模型对高质量语料的需求巨大。因此,为了训练这些AI,人们需要创造和整理大量的高质量文本数据。这个过程看似为减少人类的劳动而设计,实际上却让人类在某种程度上成了AI的“做题家”,即持续提供用于训练AI的数据。虽然这种情况和电影中的设定不同,但也呈现了一种新的依赖关系:人类的智力产物直接支持着人工智能的发展和优化。
WAIC 2024密切关注语料数据的发展。为深入探讨语料数据的策略、实践与挑战,大模型语料数据联盟、上海库帕思科技有限公司、上海市数商协会、上海市人工智能行业协会将联合举办“语料筑基,智生时代”数据主题论坛,为与会者提供深入洞察。
论坛时间:7月6日 9:30-12:30
论坛地点:上海世博中心金厅A
语料枯竭成为发展人工智能的障碍
语料库是训练AI模型的“食粮”,其质量直接决定了模型的性能和应用的广泛性。在全球范围内,从学术研究到商业应用,人工智能的发展都严重依赖于大量高质量、多样化且公正的数据,这些数据是训练精确、可靠和公正的AI系统的基础。
然而,由于采集限制、成本、维护等多种原因,高质量语料短缺正在成为全球人工智能研发中普遍存在的一个国际性难题,且短期内无法通过单纯加大资金投入解决。
导致高质量语料短缺的原因有以下几种:首先,数据的采集往往受限于版权、隐私保护法规以及数据来源的限制,导致无法广泛地收集到多样的数据样本。此外,数据的标注工作不仅成本高昂,而且需要大量的人工参与,这在很大程度上限制了数据集的规模和多样性。标注数据的准确性和一致性的维护也是一个挑战,因为不同的标注者可能会有不同的理解和判断标准。
早在2022年,就有学者指出高质量语料将会成为AI发展的制约,例如Nostalgebraist曾说过高质量的语料数据的缺失将会成为机器学习的瓶颈。近年来,不断有研究发现,由于互联网语料内容的持续下降,互联网语料数据增速已经从90年代将近100%的年增速率下降至2010年的两位数增长率,预计本世纪末,增长率将会下降至1%。
2024年6月4日,Pablo Villalobos等人在一项研究中进一步预测了高质量语料枯竭的具体时间。该研究表明,高质量数据预计将于2028年枯竭,高质量数据的缺位将会严重限制未来大模型大表现(如下图所示)。
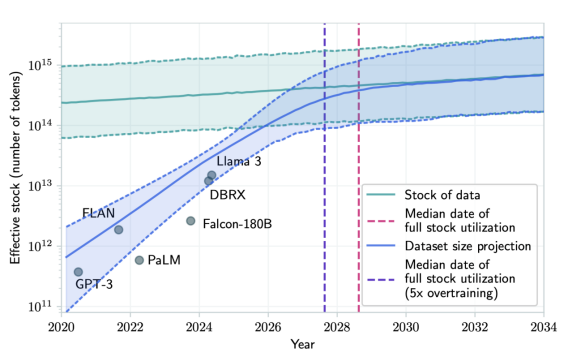
图片来源:Will we run out of data? Limits of LLM scaling based on human-generated data
为了延缓语料数据短缺,在国际上,许多研究机构和企业都在努力通过技术创新来克服这些难题,比如使用半监督学习、弱监督学习技术减少对大规模标注数据的依赖,或者开发更智能的数据增强技术来提高现有数据的利用率。同时,一些开源项目和合作平台也在推动更多高质量、可共享的数据集的生成,以减少各个研究组织之间的重复工作,提高整个行业的数据质量标准。
高质量语料短缺是全球AI研究与应用领域共同面临的问题,需要国际合作和技术创新共同解决。这不仅仅是中国独有的问题,而是一个全球性的挑战,对于推动人工智能技术的持续进步至关重要。
官方语料机构有望成为高质量语料提供“庇护所”
在面对全球性的高质量语料短缺问题时,官方语料机构的设立有望成为解决这一困境的关键所在。这类机构能够起到“庇护所”的作用,通过系统的管理与创新技术的应用,有效延缓语料枯竭的趋势,为人工智能的持续发展提供强有力的支持。
通过把控和优化多种模型合成的数据,官方语料机构能够有效管理数据的分发和使用。这种集中管理不仅保证了数据质量,还有助于防止在数据迁移学习过程中丢失关于原始人类数据分布的关键信息。
此外,机构还可以通过严格的数据审核与模型训练流程,防止因迭代输出而导致的结果同质化。结果同质化有降低模型的创新能力和适应性的风险,而官方机构的介入则可以确保每一次数据的更新和模型的迭代都能引入新的视角和多样性。
通过官方机构管理非公开高质量数据,对于机器学习也尤为重要。这些数据通常涉及敏感信息或专业领域知识,需要在确保隐私和安全的前提下进行处理和使用。通过官方机构的专业管理,这类数据可以在遵循法律和伦理标准的同时,为机器学习模型提供精确和深入的训练材料。
此外,官方语料机构还可以运用先进的数据处理技术,如data filtering和deduplication,提高数据处理的质量。这些技术可以从大量的公共语料中筛选出高质量数据,去除重复或低质量的信息。
“语料筑基,智生时代”语料专题论坛为行业带来更优解
为满足大模型发展对高质量、大规模、安全可信语料数据资源的需求,保障大模型科研攻关及相关产业生态发展,本次大会期间,上海库帕思科技有限公司将联合大模型语料数据联盟、上海市数商协会、上海市人工智能行业协会以“语料筑基,智生时代”为主题举办语料专题论坛。
论坛围绕“高质量语料数据如何高效供给赋能大模型产业发展”的话题,从专业化、链接型、前瞻性三个维度,向市场传递重构语料生态的顶层设计理念(报名请扫描海报二维码填写信息)。

本次论坛还将正式发布2024语料风云榜,遴选语料行业优秀企业和案例,打造标杆示范,鼓励更多的市场主体投身于语料产业生态布局,推动语料全行业“提质、增效、降本”发展,有效缓解语料“供给难、供给贵”的问题。
评选面向国内外人工智能语料的代表企业,围绕产品服务、研发创新、经营效率、风险合规、品牌影响力与可持续发展等指标进行评价,通过申报、预选、复选、公示、发布五个环节,最终评出2024语料风云榜。
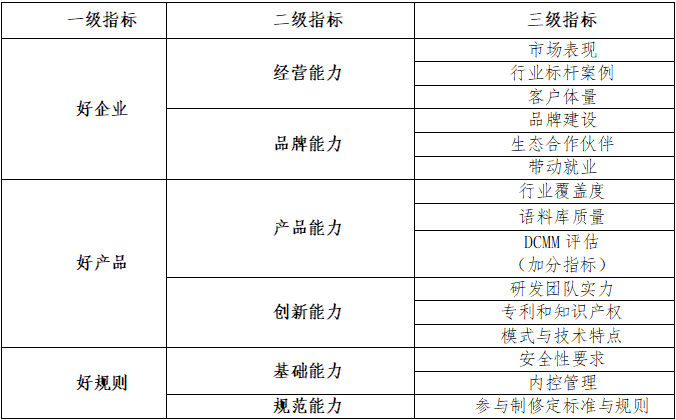
2024语料风云榜的评价标准分为“好企业、好产品、好规则”三个一级指标维度,细分至六个二级指标(经营能力、品牌能力、产品能力、创新能力、规范能力、基础能力),以及16个细化三级指标。语料产品及服务应满足主体合规、来源合规、流通合规的要求,如不满足则不可参评。
意向申报企业可从链接中下载并填写申报材料,于6月9日18点前,将申报材料发送至邮箱 liuminhao@iyiou.com 。
申报材料下载链接:
https://pan.baidu.com/s/1KzntFSNJ5cLko8qfjsc8pg?pwd=5as6 提取码: 5as6
附件一:2024语料风云榜企业申报承诺书
附件二:2024语料风云榜企业申报表
如有任何问题,欢迎与相关负责人联系,诚挚欢迎您的到来。
袁佳毅 13917988406
虎林林 18116365535
本文采摘于网络,不代表本站立场,如有侵权,请联系删稿。转载联系作者并注明出处:https://china-datacenter.com/show-666.html
